GLM-5.2 vs GPT-5.5、Claude Opus 4.8、Kimi K2.7:高级模型 Benchmark 对比
GLM-5.2 不应该只当普通国产模型看。它的 1M 上下文、128K 输出、Terminal-Bench 2.1 81.0、SWE-bench Pro 62.1 和长程工程 benchmark 信号,已经值得和 GPT-5.5、Claude Opus 4.8、Kimi K2.7 Code 放到同一层级比较。
先给结论
GLM-5.2 不应该只当普通国产模型看。它的 1M 上下文、128K 输出、Terminal-Bench 2.1 81.0、SWE-bench Pro 62.1 和长程工程 benchmark 信号,已经值得和 GPT-5.5、Claude Opus 4.8、Kimi K2.7 Code 放到同一层级比较。
适合你,如果
- • 正在搜索 GLM-5.2 vs GPT-5.5、GLM-5.2 vs Claude Opus 4.8、GLM-5.2 vs Kimi K2.7
- • 想评估国产模型是否能进入高级 coding agent 工作流
- • 需要把 benchmark、上下文、最大输出和真实工程任务放在一起判断
不适合你,如果
- • 只想找一个普通聊天助手
- • 希望不同厂商 benchmark 可以无条件硬排名
- • 不打算用真实代码库或业务任务做回归验证
按场景快速决策
| 使用场景 | 推荐 | 原因 | 注意点 |
|---|---|---|---|
| 超长代码库 / 长程重构 | GLM-5.2 / Claude Opus 4.8 | 两者都明确支持 1M 上下文,GLM-5.2 还给出 Terminal-Bench 2.1 和 SWE-bench Pro 信号 | 必须用你的真实 repo 验证上下文召回和改代码质量 |
| OpenAI 工具链 / Codex / 终端代理 | GPT-5.5 | OpenAI 生态、工具调用和终端工作流迁移成本更低 | 上下文、价格和可用性要以 OpenAI 当前模型页为准 |
| 闭源旗舰工程交付 | Claude Opus 4.8 | Anthropic 官方定位就是复杂推理、长程 agentic coding 和高自治任务 | 价格、账号和网络环境可能限制落地 |
| Kimi 生态代码模型 / 高速输出 | Kimi K2.7 Code Highspeed | Kimi 官方强调 K2.7 Code 是当前最强 coding model,Highspeed 版本输出速度更高 | 官方模型列表暂未披露可同表横比的完整 benchmark |
不同人群怎么选
先把 GLM-5.2 和 Opus 4.8 放进同一套 repo 压测
这组最能验证长程工程能力,而不是普通聊天体感。
用同一个跨文件重构任务记录成功率、修正次数、耗时和测试通过率。
GPT-5.5 继续做主力,GLM-5.2 做长上下文对照
已有 OpenAI/Codex 生态时,迁移成本本身就是优势。
挑 3 个 300K token 以上的代码库或长文档任务对照测试。
GLM-5.2 是第一优先级
1M 上下文和长程工程 benchmark 是当前更稀缺的国产模型信号。
再加入 Kimi K2.7 Code、DeepSeek、通义做成本和中文生态对比。
Kimi K2.7 Code 先测速度和生态,GLM-5.2 测长任务
两者不是同一个卖点,硬比总分意义不大。
把代码生成速度、上下文稳定性和最终可运行率分开记录。
把本页作为 GLM-5.2 pillar page
三个用户明确搜索组合可以集中到同一个高权重页面。
等 GSC 出现展示后,再拆 GLM-5.2 vs GPT-5.5 / Opus 4.8 / Kimi K2.7 三篇短页。
按你的高端模型任务快速选
先选你最在意的任务,再决定先压测哪一个模型。
下一步怎么做
常见问题
GLM-5.2 能超过 GPT-5.5 吗?
不能简单说全面超过。Z.ai 官方材料显示 GLM-5.2 在长程工程 benchmark 上有强信号,并称多个 benchmark 超过 GPT-5.5;但 GPT-5.5 仍有 OpenAI 生态、工具链和通用专业任务优势。
GLM-5.2 和 Claude Opus 4.8 谁更适合写代码?
Claude Opus 4.8 是闭源旗舰里的强参照,适合预算充足和成熟 API 工作流;GLM-5.2 的优势是 1M 上下文、Terminal-Bench 2.1 81.0、SWE-bench Pro 62.1 和国产模型落地潜力。
GLM-5.2 vs Kimi K2.7 Code 怎么选?
大代码库、长程重构和 coding agent 先测 GLM-5.2;Kimi 生态、高速输出和 256K 代码任务可以测 Kimi K2.7 Code / Highspeed。
Kimi K2.7 Code 有公开 benchmark 吗?
Kimi 官方模型列表目前披露了定位、256K 上下文和 Highspeed 速度,但未给出能和 GLM-5.2 直接同表横比的完整 Terminal-Bench / SWE-bench Pro 数据。
GLM-5.2 是否适合替代 Claude Code 或 Codex?
不要直接替代。应该用同一套真实 repo 测需求理解、代码修改、测试修复、diff 质量、失败恢复和总成本,再决定是否替换或分层路由。
继续看这些对比
这篇对比怎么使用
对比页不只回答谁更强,而是回答你在什么预算、什么任务、什么团队约束下应该换工具或继续用原方案。
如果页面给出赢家,也只是针对当前场景的默认建议;遇到隐私、中文、额度、采购或 API 成本要求时,需要按文中的限制重新判断。
先说结论:GLM-5.2 应该和高级模型放在一起看
如果你在搜 GLM-5.2 vs Kimi K2.7、GLM-5.2 vs GPT-5.5、GLM-5.2 vs Claude Opus 4.8,不要把 GLM-5.2 当成普通“国产模型更新”来看。
更准确的定位是:GLM-5.2 是面向长程工程任务、1M 上下文和代码 Agent 的国产旗舰模型,最应该和 GPT-5.5、Claude Opus 4.8、Kimi K2.7 Code 这种高级模型放到同一张表里比较。
先给结论:
| 你的核心问题 | 更应该先看 |
|---|---|
| 想测试国产模型能不能进高级 coding agent 工作流 | GLM-5.2 |
| 想要闭源旗舰、终端执行和 OpenAI 工具生态 | GPT-5.5 / OpenAI 生态 |
| 想要最稳的长程 agentic coding 和企业 API | Claude Opus 4.8 |
| 想要 Kimi 生态里的代码模型和更快输出 | Kimi K2.7 Code / Highspeed |
一句话:GLM-5.2 的流量价值不在“又一个国产模型”,而在“国产模型第一次值得进入 GPT-5.5 / Opus 4.8 / Kimi K2.7 Code 这种高端对比搜索”。
核心 Benchmark 速览
先看官方图,再看我整理出的数字表。图片负责确认来源和直观冲击,表格负责把信息变成可搜索、可引用、可复查的结构化结论。
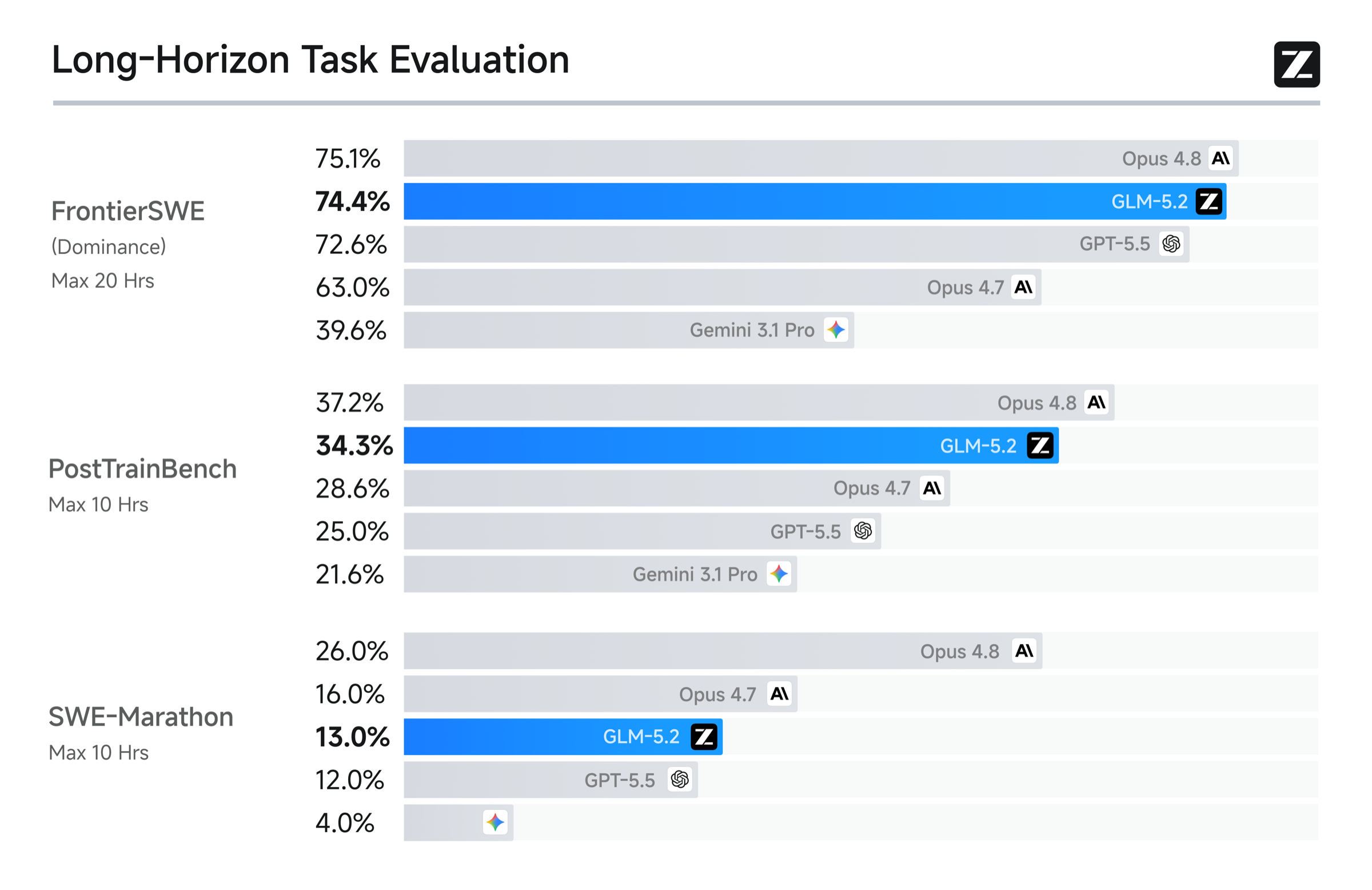
| 指标 | GLM-5.2 | GPT-5.5 | Claude Opus 4.8 | Kimi K2.7 Code | 怎么解读 |
|---|---|---|---|---|---|
| 上下文窗口 | 1M | OpenAI 模型页显示当前 GPT 旗舰线有 400K 级上下文条目;GPT-5.5 另看系统卡 | 1M | 256K | GLM-5.2 和 Opus 4.8 更适合超长代码库/文档任务 |
| 最大输出 | 128K | 128K 级输出条目 | 128K | 官方文档未单独披露 | 长报告、代码生成、迁移说明里 GLM/Claude 更有明确上限 |
| FrontierSWE (Dominance, Max 20 Hrs) | 74.4% | 72.6% | 75.1% | 未披露同表分数 | GLM-5.2 只比 Opus 4.8 低 0.7 点,并高于 GPT-5.5 |
| PostTrainBench (Max 10 Hrs) | 34.3% | 25.0% | 37.2% | 未披露同表分数 | GLM-5.2 明显高于 GPT-5.5,接近 Opus 4.8 |
| SWE-Marathon (Max 10 Hrs) | 13.0% | 12.0% | 26.0% | 未披露同表分数 | Opus 4.8 明显领先,GLM-5.2 略高于 GPT-5.5 |
| SWE-bench Pro | 62.1 | 58.6 | 69.2 | 未披露同表分数 | GLM-5.2 高于 GPT-5.5,但低于 Opus 4.8 |
| Terminal-Bench 2.1 | 81.0 | 84.0 | 85.0 | 未披露同表分数 | GLM-5.2 已接近闭源旗舰终端任务区间 |
| ProgramBench | 63.7 | 70.8 | 71.9 | 未披露同表分数 | 这一项 Opus 4.8 / GPT-5.5 仍更强 |
| MCP-Atlas | 77.0 | 75.3 | 77.8 | 未披露同表分数 | GLM-5.2 基本进入 Opus 4.8 同区间 |
| 官方定位 | 长程任务、项目级工程、代码 Agent | 通用旗舰与工具生态 | 复杂推理、长程 agentic coding、高自治任务 | Kimi 当前最强 coding model | 四者不是同一种产品形态,选型要按任务分层 |
重要说明:上面可直接写数字的 GLM-5.2 / GPT-5.5 / Claude Opus 4.8 项,来自 Z.ai 官方页与官方图表;Kimi K2.7 Code 官方模型列表没有披露同表 benchmark,因此只写“未披露同表分数”。不同厂商的 benchmark 版本、测试协议和工具配置可能不同,本文不把所有数字硬凑成一个总分。
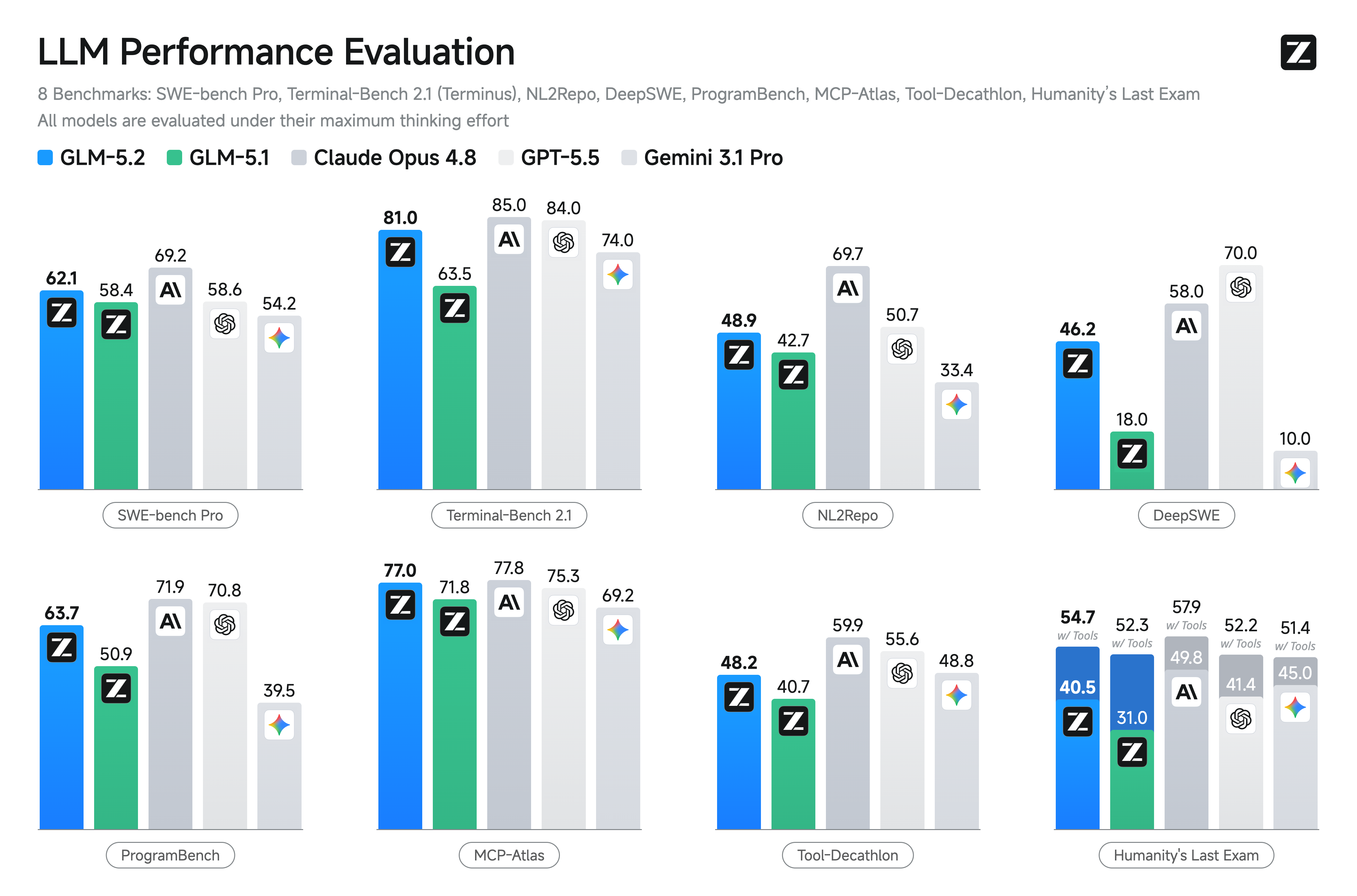
GLM-5.2 vs Claude Opus 4.8:最应该重点对比的一组
如果只选一组高级对比,我会优先做 GLM-5.2 vs Claude Opus 4.8。
原因很简单:两者都把重点放在长程工程和 agentic coding,而不是普通聊天。
| 维度 | GLM-5.2 | Claude Opus 4.8 |
|---|---|---|
| 官方定位 | 长程任务时代的旗舰基础模型,强调项目级工程上下文和长期任务稳定执行 | Anthropic 最强 Opus 级模型,面向复杂推理、长程 agentic coding 和高自治工作 |
| 上下文 | 1M | 1M |
| 最大输出 | 128K | 128K |
| 长程工程信号 | FrontierSWE 74.4%、PostTrainBench 34.3%、SWE-Marathon 13.0% | FrontierSWE 75.1%、PostTrainBench 37.2%、SWE-Marathon 26.0% |
| 代码/终端信号 | Terminal-Bench 2.1 81.0,SWE-bench Pro 62.1,MCP-Atlas 77.0 | Terminal-Bench 2.1 85.0,SWE-bench Pro 69.2,MCP-Atlas 77.8 |
| 适合谁 | 想测试国产/开放模型进入复杂工程工作流的团队 | 预算充足、需要闭源旗舰稳定性的团队 |
| 最大风险 | 仍要用真实代码库验证工具链、SDK、稳定性和成本 | 价格、地区可用性、企业账号和网络环境 |
我的判断:Claude Opus 4.8 仍是闭源旗舰工程任务的强参照;GLM-5.2 的意义是它第一次把国产模型拉到了这个对比桌面上。
如果你是开发团队,不要只问“哪个分数高”。更好的压测方式是:
- 让两个模型读同一个真实代码库;
- 给同一个跨文件重构任务;
- 限定同样的 token、时间和工具权限;
- 要求它们先写计划,再改代码,再跑测试,再解释 diff;
- 记录成功率、人工修正次数、总耗时和最终代码质量。
GLM-5.2 vs GPT-5.5:一个看长程工程,一个看 OpenAI 工具生态
GLM-5.2 vs GPT-5.5 这组更适合做“国产长程工程模型 vs OpenAI 旗舰生态”的对比。
| 维度 | GLM-5.2 | GPT-5.5 |
|---|---|---|
| 强项 | 1M 上下文、长程代码任务、项目级工程上下文 | OpenAI 生态、工具调用、终端/agent 工作流、专业任务覆盖 |
| GLM-5.2 领先项 | FrontierSWE 74.4% vs 72.6%、PostTrainBench 34.3% vs 25.0%、SWE-bench Pro 62.1 vs 58.6、MCP-Atlas 77.0 vs 75.3 | 在这些 Z.ai 图表项里落后 GLM-5.2 |
| GPT-5.5 领先项 | Terminal-Bench 2.1 81.0 vs 84.0、ProgramBench 63.7 vs 70.8 | 终端和 ProgramBench 仍有优势 |
| 适合场景 | 想把国产模型放进 coding agent、企业私有/开放生态评估 | 已经使用 OpenAI API、Codex 或 OpenAI 工具链 |
| 决策关键 | 能否在你的真实 repo 里稳定完成长任务 | 工具链、生态、可靠性和团队使用习惯 |
如果你只看一句结论:GLM-5.2 更像“国产长程工程模型候选”,GPT-5.5 更像“OpenAI 生态里的综合旗舰候选”。
这两者不应该只用单个跑分决定。真正会影响选择的是:
- 你是不是已经有 OpenAI/Codex 工作流;
- 你是否需要国内可用、国产模型或企业部署选项;
- 你是否经常处理 300K 以上的代码库/日志/长文档;
- 你能不能接受闭源旗舰价格和网络环境约束;
- 你的任务是“写答案”,还是“完成工程交付”。
GLM-5.2 vs Kimi K2.7 Code:国产高级模型内部要分工看
GLM-5.2 vs Kimi K2.7 Code 的搜索价值会很高,但页面结论必须谨慎:Kimi 官方模型列表目前明确写了 K2.7 Code 是 Kimi 当前最强代码模型,支持 256K 上下文,并有 Highspeed 版本;但没有在模型列表页给出可直接和 GLM-5.2 同表横比的 Terminal-Bench / SWE-bench Pro 分数。
| 维度 | GLM-5.2 | Kimi K2.7 Code |
|---|---|---|
| 官方定位 | 长程任务、项目级工程上下文、1M 代码 Agent | Kimi 当前最强 coding model,长上下文指令跟随和代码任务成功率更高 |
| 上下文 | 1M | 256K |
| 速度 | 官方重点在长任务稳定性和工程能力 | Highspeed 版本约 180 tokens/s,短上下文最高约 260 tokens/s |
| 公开 benchmark | GLM-5.2 官方页披露 Terminal-Bench 2.1 81.0、SWE-bench Pro 62.1 等 | 模型列表页暂未披露同表分数 |
| 更适合 | 大代码库、长程重构、工程标准约束 | Kimi 生态用户、代码生成速度、中文产品链路 |
我的建议:GLM-5.2 主打“长程工程能力”,Kimi K2.7 Code 主打“Kimi 生态里的代码模型与速度体验”。 如果你要做网站内容,不要把 Kimi K2.7 写成“被 GLM-5.2 碾压”;更好的写法是:
- GLM-5.2:强调 1M、Terminal-Bench 2.1、SWE-bench Pro、FrontierSWE;
- Kimi K2.7 Code:强调 256K、Kimi 当前最强 coding model、Highspeed 输出速度;
- 最终建议:用同一套真实代码任务测试,而不是拿未披露分数硬排名。
四个模型怎么选?
| 你的任务 | 首选 | 备选 | 理由 |
|---|---|---|---|
| 超长代码库理解和重构 | GLM-5.2 / Claude Opus 4.8 | GPT-5.5 | 1M 上下文和长程工程信号更关键 |
| 终端代理、工具链和 OpenAI 生态 | GPT-5.5 | Claude Opus 4.8 / GLM-5.2 | 已有 OpenAI/Codex 生态时迁移成本最低 |
| 闭源旗舰工程交付 | Claude Opus 4.8 | GPT-5.5 | Anthropic 官方定位更偏复杂推理和 agentic coding |
| 国产 coding agent 评估 | GLM-5.2 | Kimi K2.7 Code / DeepSeek | GLM-5.2 的 1M 和工程 benchmark 更突出 |
| Kimi 生态和高速代码输出 | Kimi K2.7 Code Highspeed | GLM-5.2 | Kimi 官方强调更可靠长上下文指令跟随和高速版本 |
| 中文团队低迁移成本 | GLM-5.2 / Kimi K2.7 | DeepSeek / 通义 | 国内可用性、中文体验和 API 接入要一起看 |
我建议网站怎么处理 GLM-5.2 流量
这一页应该作为 GLM-5.2 的高端对比主入口,不要只做单篇新闻。
内容集群可以这样铺:
- 主页面:GLM-5.2 vs GPT-5.5 vs Claude Opus 4.8 vs Kimi K2.7 Code。
目标关键词:GLM-5.2 vs GPT-5.5、GLM-5.2 vs Claude Opus 4.8、GLM-5.2 vs Kimi K2.7。
- 国产模型页导流:国产大模型怎么选 里把 GLM 从“值得关注”升级为“工程化/Agent 重点候选”。
- 旧 GLM-5 页面导流:MiniMax M2.5 vs Kimi K2.5 vs GLM-5 顶部加更新提示,把想看新模型的人引到 GLM-5.2。
- 模型资料页:给 GLM-5.2 单独模型页,承接
/models的搜索和站内对比。
- 后续可以拆三篇短页:如果 GSC 出现明确 query,再拆:
- GLM-5.2 vs GPT-5.5
- GLM-5.2 vs Claude Opus 4.8
- GLM-5.2 vs Kimi K2.7 Code
现在不急着拆三篇,是因为新站内容量还不大,先用一篇权重集中的 pillar page 更稳。等 Search Console 确认哪个关键词有展示,再拆分不会互相抢排名。
FAQ
GLM-5.2 能超过 GPT-5.5 吗?
不能简单说“全面超过”。Z.ai 官方材料称 GLM-5.2 在 FrontierSWE、PostTrainBench、SWE-Marathon 等长程工程 benchmark 上有很强信号,并在多个 benchmark 上超过 GPT-5.5;但 GPT-5.5 仍有 OpenAI 生态、工具链和通用专业任务优势。实际选择要看你的任务是不是长程工程。
GLM-5.2 和 Claude Opus 4.8 谁更适合写代码?
Claude Opus 4.8 仍是闭源旗舰里的强参照,尤其适合预算充足、需要稳定 API 和成熟工具链的团队。GLM-5.2 的优势是 1M 上下文、官方公开的 Terminal-Bench 2.1 / SWE-bench Pro 信号,以及国产模型进入长程工程任务的潜力。
GLM-5.2 vs Kimi K2.7 Code 怎么选?
如果你的核心是大代码库、跨文件重构、长程 Agent 任务,先测 GLM-5.2;如果你已经在 Kimi 生态里,重视代码输出速度和 Kimi 的中文产品链路,Kimi K2.7 Code / Highspeed 值得测试。
Kimi K2.7 Code 有公开 benchmark 吗?
Kimi 官方模型列表页目前主要披露定位、256K 上下文和 Highspeed 输出速度,没有给出能和 GLM-5.2 直接同表横比的完整 Terminal-Bench / SWE-bench Pro 数据。因此本文不编造 Kimi K2.7 Code 分数。
GLM-5.2 是否适合替代 Claude Code 或 Codex?
不要直接替代。更稳的做法是把 GLM-5.2 放进同一套真实 repo 压测:需求理解、代码修改、测试修复、diff 质量、失败恢复和总成本都记录下来。只有真实项目胜率稳定,才考虑替换或分层路由。
参考来源
- Z.ai GLM-5.2 官方文档
- Z.ai GLM-5.2 官方博客
- Kimi 官方模型列表
- Anthropic Claude Models Overview
- OpenAI API Models
- OpenAI: Introducing GPT-5.5
- OpenAI GPT-5.5 System Card
更新时间:2026 年 6 月 28 日。模型上下文、价格、API ID 和 benchmark 会频繁变化,正式采购或上线前请以官方文档和你的真实任务回归为准。
继续看这些
如果你还没做决定,下一步最有效的方式不是换一个搜索词,而是把相关评测和同类对比一起看完。
Claude 评测:最适合长文写作和深度分析的 AI
Anthropic Claude 全面评测,看看这个主打安全与深度的 AI 助手到底实力如何。
继续阅读Kimi 评测:最强中文 AI 助手?月之暗面的实力到底如何
深度评测 Kimi(月之暗面),看看这款国产 AI 在中文场景下是否能替代 ChatGPT。
继续阅读中文写作 AI 哪个好?2026 ChatGPT、Claude、Kimi、豆包、DeepSeek 对比
中文写作 AI 怎么选?按公众号长文、小红书文案、报告、公文、改稿和长文档总结,对比 ChatGPT、Claude、Kimi、豆包、DeepSeek 的适用场景。
继续阅读ChatGPT、Claude、Gemini、DeepSeek 怎么选?2026 大模型实用对比
ChatGPT、Claude、Gemini、DeepSeek 哪个更适合你?从写作、编程、长文本、中文能力、价格、国内使用和 API 场景对比,给出不同人群推荐。
继续阅读更多相关决策页
Claude 评测:最适合长文写作和深度分析的 AI
Anthropic Claude 全面评测,看看这个主打安全与深度的 AI 助手到底实力如何。
Kimi 评测:最强中文 AI 助手?月之暗面的实力到底如何
深度评测 Kimi(月之暗面),看看这款国产 AI 在中文场景下是否能替代 ChatGPT。
中文写作 AI 哪个好?2026 ChatGPT、Claude、Kimi、豆包、DeepSeek 对比
中文写作 AI 怎么选?按公众号长文、小红书文案、报告、公文、改稿和长文档总结,对比 ChatGPT、Claude、Kimi、豆包、DeepSeek 的适用场景。
ChatGPT、Claude、Gemini、DeepSeek 怎么选?2026 大模型实用对比
ChatGPT、Claude、Gemini、DeepSeek 哪个更适合你?从写作、编程、长文本、中文能力、价格、国内使用和 API 场景对比,给出不同人群推荐。
真实使用反馈